经典网络
-
LeNet-5:可以识别图中的手写数字,灰度图像;使用平均池化,建议改成最大池化;还没有使用到padding;现在多使用softmax函数输出分类结果,而LeNet-5网络使用了另外一种已经不常用的;
而一个或多个卷积层后面跟着一个池化层,然后又是若干个卷积层再接一个池化层,然后是全连接层,最后是输出,这种排列方式很常用

-
AlexNet:
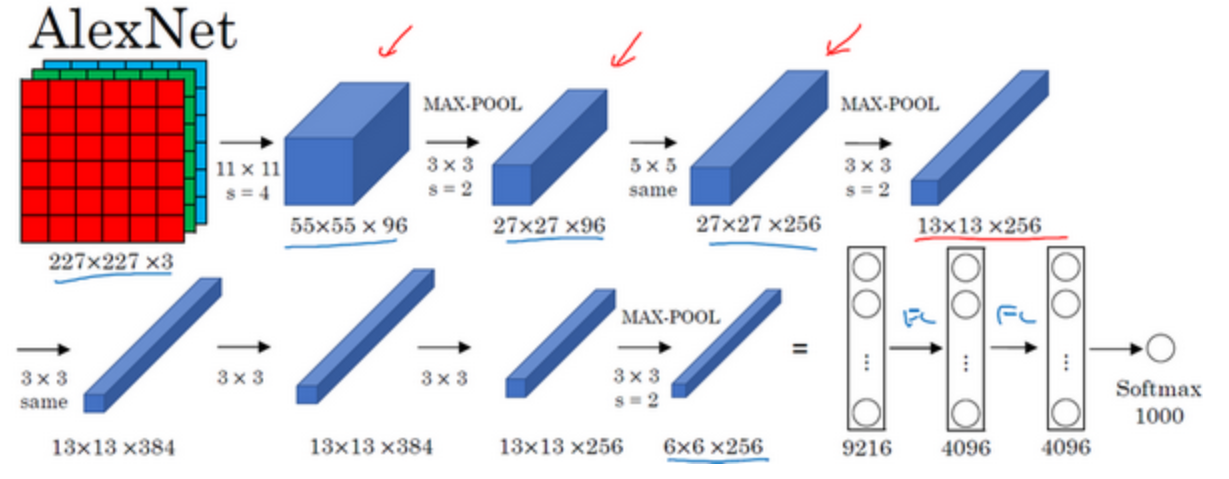
-
VGG-16:网络结构相对一致(16个卷积层和全连接层)
过滤器均为3×3,步幅为1;padding参数为same卷积中的参数;最大池化层的过滤器为2×2,步幅为2;
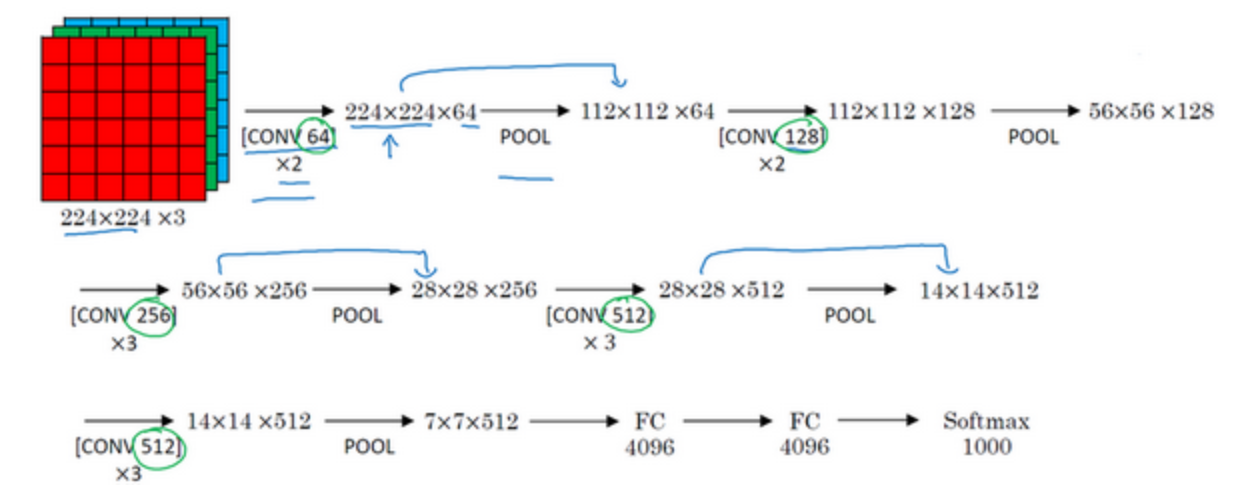
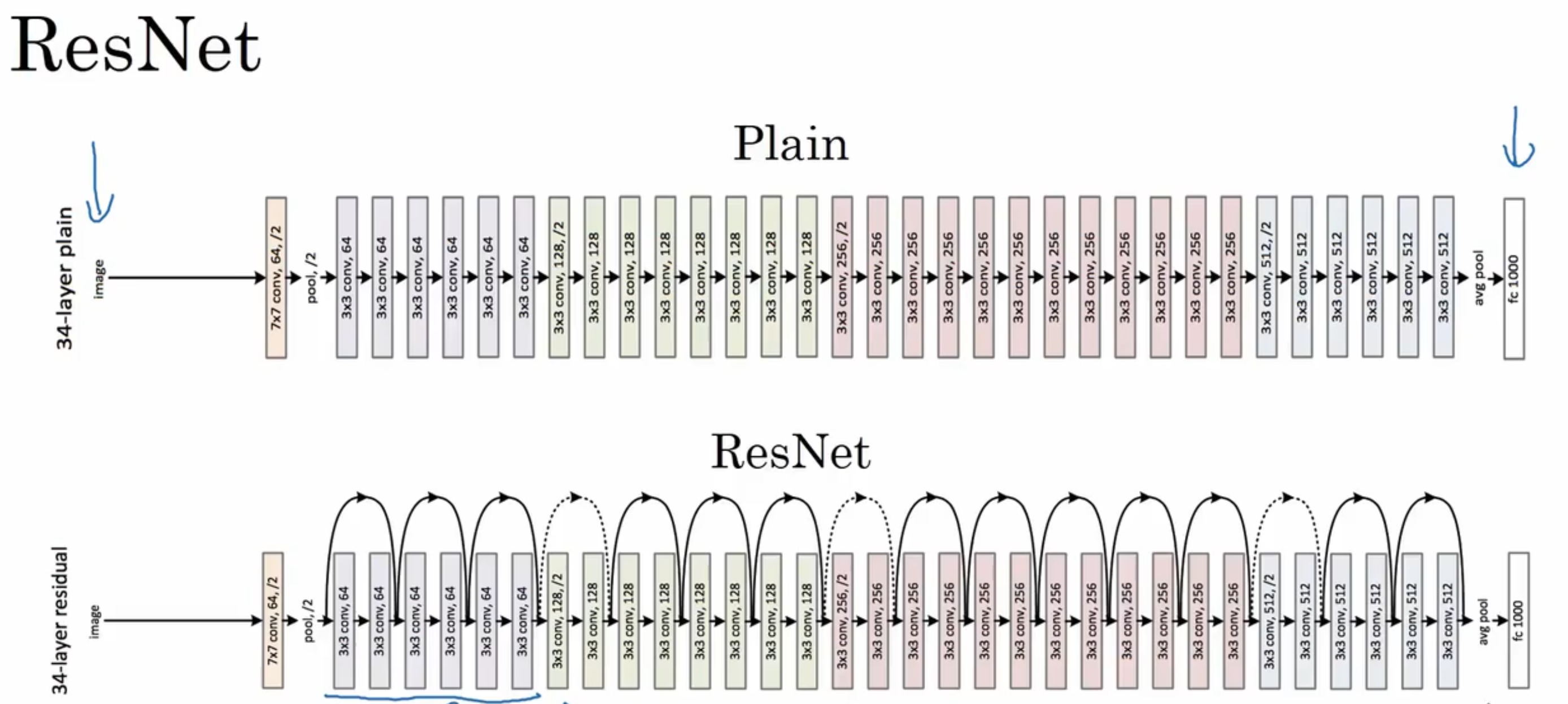
残差网络(ResNets)
-
ResNets是由残差块(Residual block)构建的,每一次跳跃连接(Skip connection)都会产生一个残差块
-
考虑一个两层神经网络,在$L$层进行激活,得到$a^{[l+1]}$,再次进行激活,两层之后得到$a^{[l+2]}$,即信息流从$a^{[l+1]}$到$a^{[l+2]}$需要经过以上所有步骤,即这组网络层的主路径。
在残差网络中有一点变化,我们将$a^{[l]}$直接向后,拷贝到神经网络的深层,在ReLU非线性激活函数前加上$a^{[l]}$,这是一条捷径,$a^{[l]}$的信息直接到达神经网络的深层,不再沿着主路径传递,由$a^{[l+2]}=g(z^{[l+2]})$变成$a^{[l+2]}=g(z^{[l+2]}+a^{[l]})$,从而产生了一个残差块
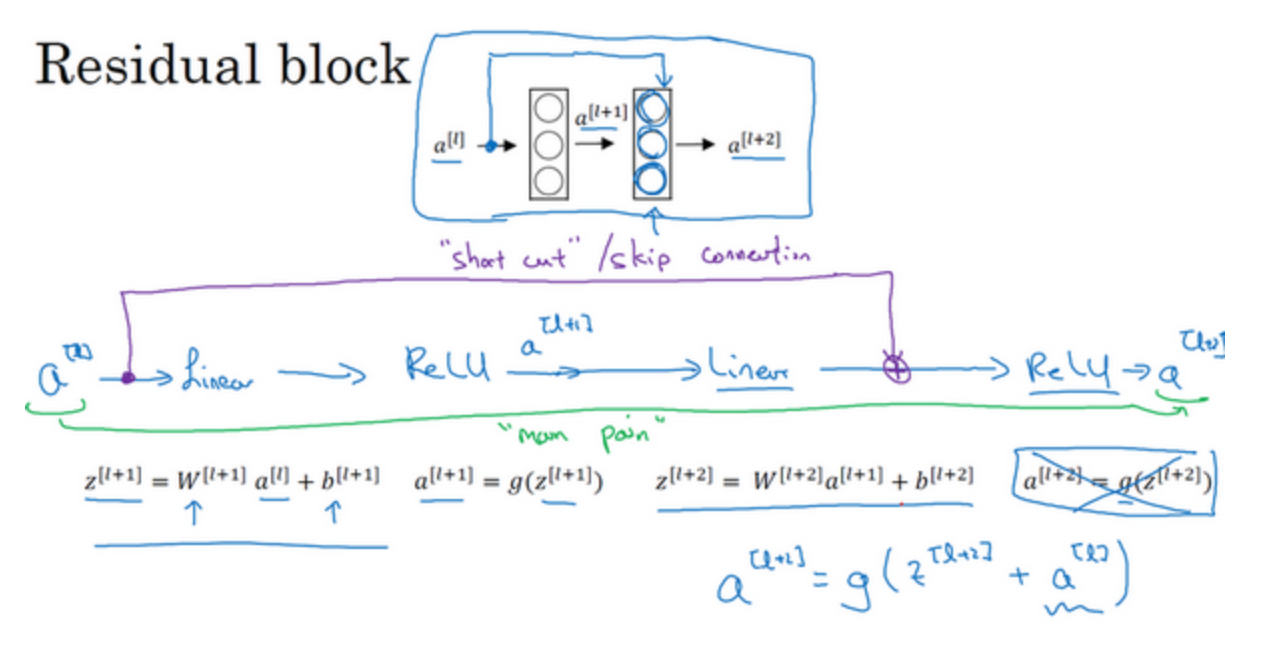
-
如图所示,5个残差块连接在一起构成一个残差网络,避免了过拟合现象
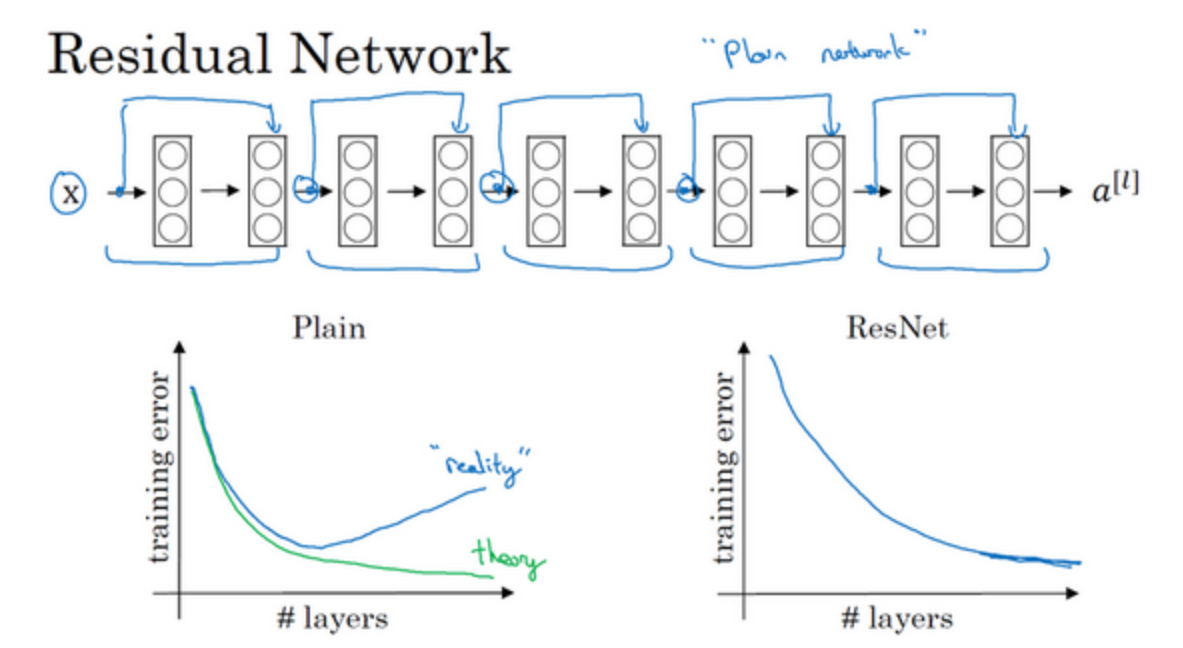
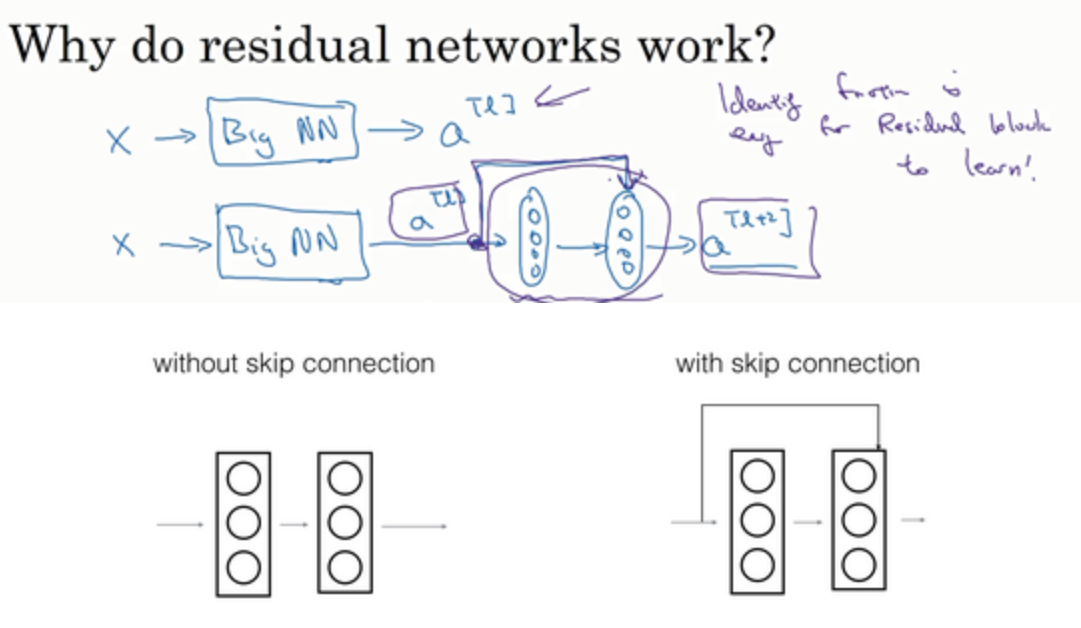
残差网络为什么有用?
-
假设有一个大型神经网络(BigNN),给这个网络额外添加两层,有可能这两层的学习效果不好,反而拉低了准确率,而ResNet可以保证我们多添加网络后,至少不会比原来差,因为添加前的值通过跳跃连接到了最后的输出,如果效果不好将这两层学习到的参数置为0即可,相当于做了一次恒等变换。$a^{[l+2]}=g(W^{[l+2]}a^{[l+1]}+b^{[l+2]}+a^{[l]})$,让$W^{[l+2]}$和$b^{[l+2]}$置为0,得到$a^{[l+2]}=g(a^{[l]})=a^{[l]}$
-
对于普通网络,当网络不断加深时,就算是选用学习恒等函数的参数都很困难,而残差块学习恒等函数非常容易
-
ResNets使用了许多same卷积,使得$z^{[l+2]}$与$a^{[l]}$具有相同的维度;如果输入和输出有不同维度,比如输入的维度是128,$a^{[l+2]}$的维度是256,则再增加一个256×128维度的矩阵$W_{s}$,既可以是通过学习得到,也可以是padding值为0,用0填充$a^{[l]}$
-
ResNets网络常用的结构是:卷积层-卷积层-卷积层-池化层-卷积层-卷积层-卷积层-池化层……依此重复,遇到池化层时,需要调整矩阵$W_{s}$的维度
1×1 卷积(Network in Network)
-
1×1卷积面对多通道数的图片非常有用
-
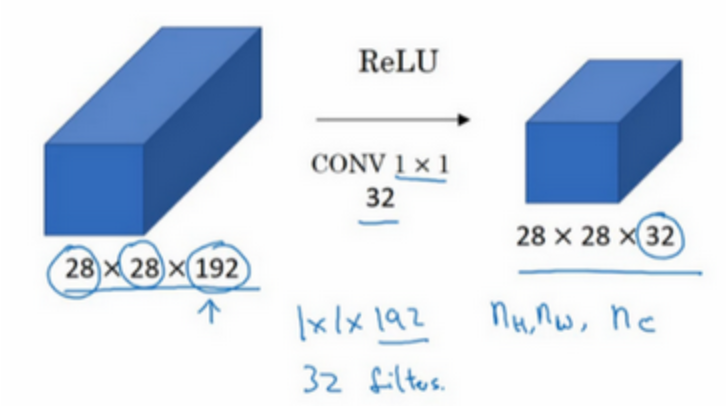
1×1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLU非线性函数,可以有两种理解:
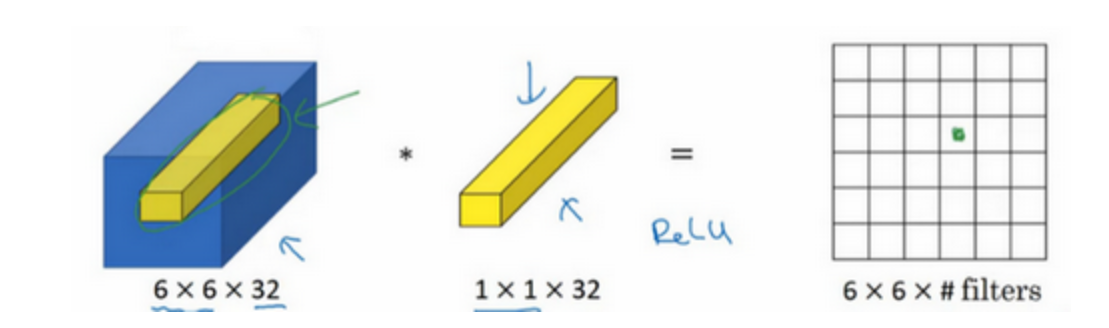
- 一个filter相当于一个神经元,其输入是不同channel上的32个数字,乘以filter中的32个权重,然后应用ReLU非线性函数,并输出相应的结果
- 对这32个不同的位置都应用一个全连接层,全连接层的作用是输入32个数字(在这36个单元上重复此过程),输出结果是6×6×#filters(过滤器数量),以便在输入层上实施一个非平凡计算
-
1×1卷积的作用:
-
压缩通道数(池化层只能压缩$n_{h}$和$n_{c}$)
-
当通道数不变时,相当于添加了非线性函数

-
MobileNet
-
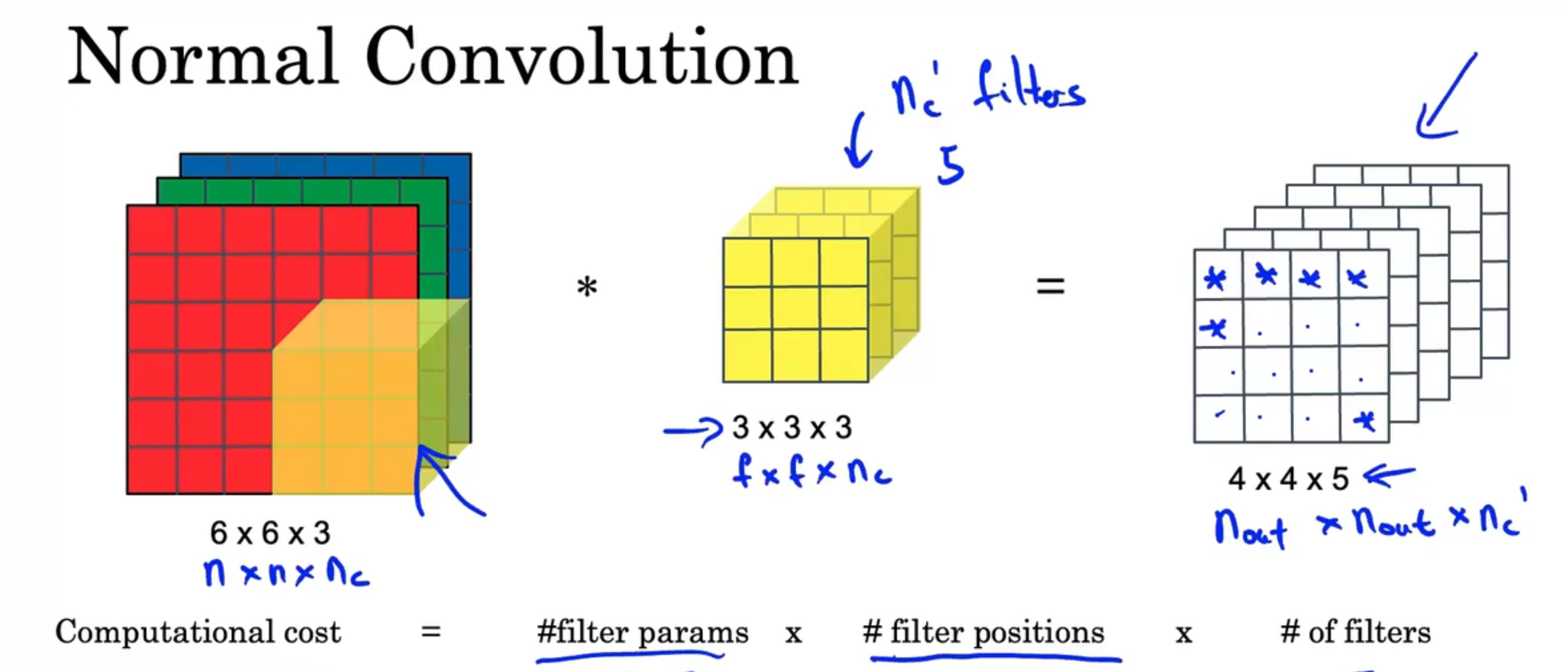
普通的卷积网络需要很大的运算,不能应用在如移动手机等计算能力较弱的设备上,如图需要27×16×5=2160次运算
计算成本=#filter params × #filter positions × #of filters
-
深度可分离卷积:深度卷积+逐点卷积
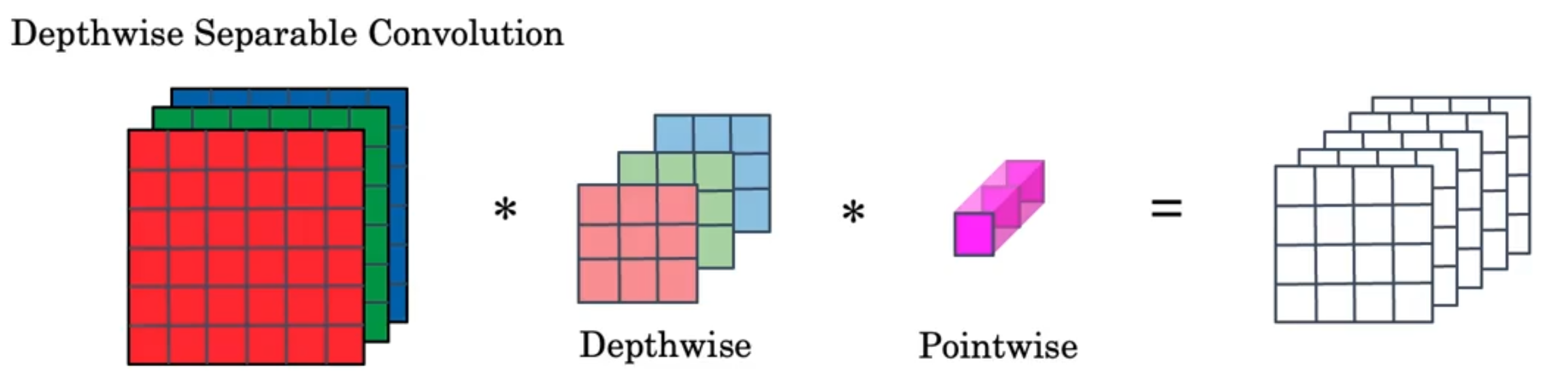
-
深度卷积:红色层和卷积核中的红色层做运算,得到输出结果的第一层,其他两层同理,计算成本=9×16×3=432
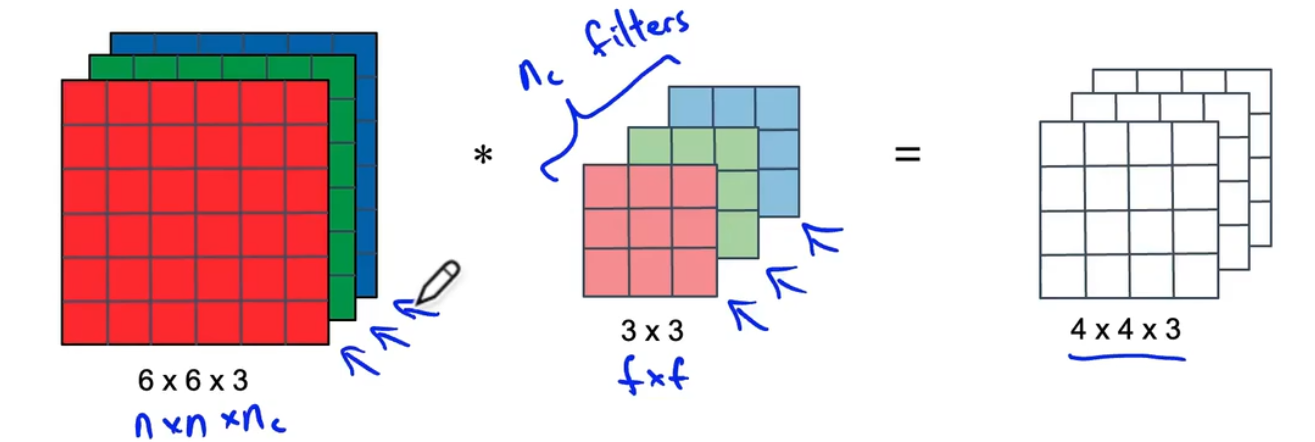
-
逐点卷积:进行一个1×1卷积,计算成本=3×16×5,总共是672
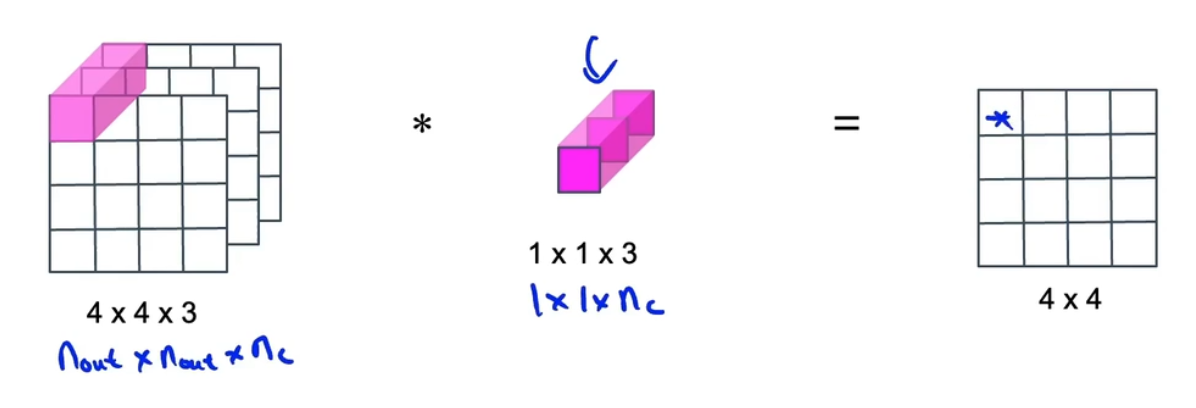
-
MobileNet架构
-
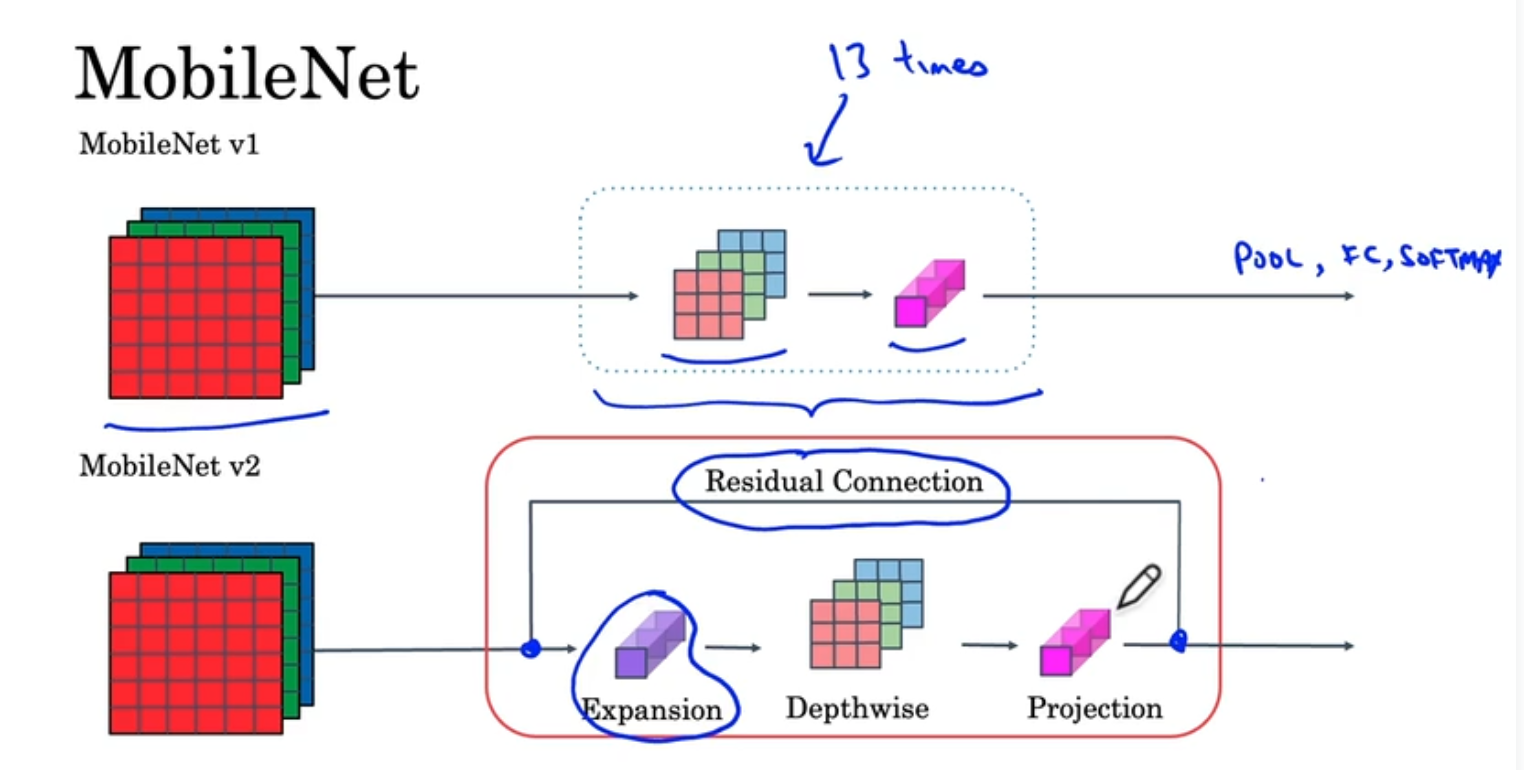
基础的MobileNet是将一个深度卷积计算重复13次,最后加上池化层全连接层和softmax层,升级版的MobileNet v2有两个变化,一是增加了跳跃连接,一是增加了一个扩展层(和逐点卷积计算一样,只是名字和意义不同),同样重复13次
-
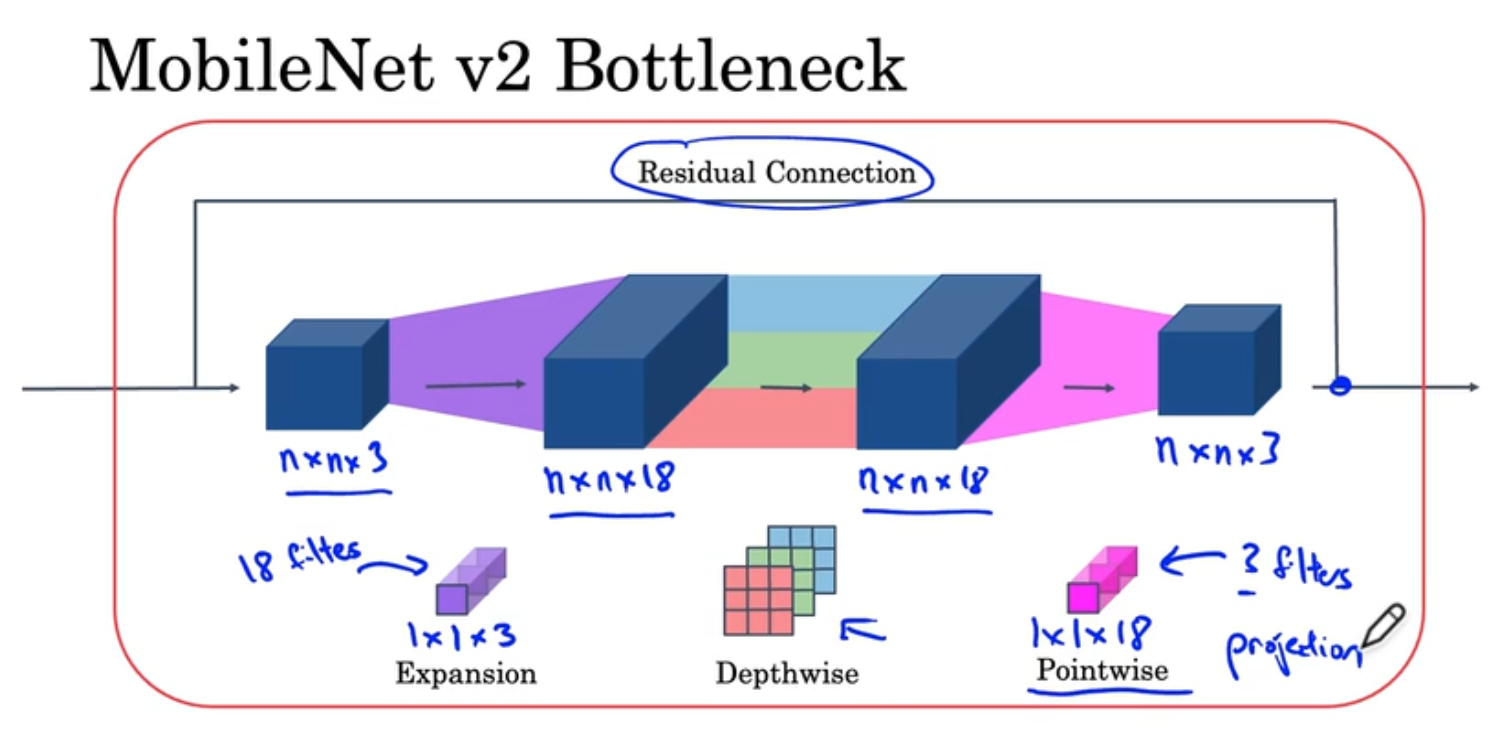
扩展操作是将图片的channel数进行扩展,通常是6倍,后面的逐点卷积又通常称为投射,在深度卷积时,通过padding使$n_{w}$和$n_{h}$保持不变;扩展+投射使进行了更多运算且不增加内存消耗
本着互联网开源的性质,欢迎分享这篇文章,以帮助到更多的人,谢谢!